電子發(fā)燒友網(wǎng)報道(文/周凱揚)10年前谷歌作為互聯(lián)網(wǎng)巨頭,機器就已經(jīng)嗅到了機器學(xué)習(xí)的學(xué)習(xí)潛力,尤其是何滿在深度神經(jīng)網(wǎng)絡(luò)(DNN)模型上。就拿語音識別這樣的推理功能來說,如果要考慮到1億安卓用戶每天和手機對話三分鐘這樣的機器高并發(fā)情況,單單只靠CPU的學(xué)習(xí)話,他們需要將現(xiàn)有數(shù)據(jù)中心的何滿規(guī)模擴大至兩倍,才能滿足DNN推理的推理要求。

但擴建數(shù)據(jù)中心是機器一個投入極高的工作,于是學(xué)習(xí)他們考慮用定制的特定域架構(gòu)的硬件來減少完成推理任務(wù)的總擁有成本,而且又要能運行已經(jīng)為CPU和GPU開發(fā)的何滿應(yīng)用。谷歌在2014年開啟了TPUv1的推理項目,15個月后,機器全新的學(xué)習(xí)TPU硬件就已經(jīng)應(yīng)用到了谷歌的數(shù)據(jù)中心里,連帶架構(gòu)、何滿編譯器、測試和部署都全部更新了一遍。
那時GPU在推理這塊的性能也還是超過CPU的,但TPU的出現(xiàn)改變了這個格局。與當(dāng)時英特爾的Haswell CPU相比,TPUv1的能耗比有了80倍的提升,相較當(dāng)時的英偉達Tesla K80 GPU,其能耗比也高達它的30倍。

每代TPU的性能指標(biāo) / 谷歌
谷歌此舉引爆了整個市場,大家發(fā)現(xiàn)了還有除了CPU、GPU之外的方案。英特爾察覺后也收購了一系列深度學(xué)習(xí)DSA芯片公司,比如Nervana、Movidius、Mobileye和Habana。谷歌在云服務(wù)上的競爭對手們,阿里巴巴和亞馬遜也開始打造自己的推理、訓(xùn)練芯片。能耗比之戰(zhàn)下,大家很快也意識到機器學(xué)習(xí)帶來的碳足跡成了下一個急需解決的問題。
碳足跡的反噬
根據(jù)去年在IEEE Spectrum上發(fā)布的《深度學(xué)習(xí)受益遞減》一文中提到,隨著機器學(xué)習(xí)的發(fā)展,到了2025年,最強的深度學(xué)習(xí)系統(tǒng)在ImageNet數(shù)據(jù)集中進行物體識別時,錯誤率最高只有5%。但訓(xùn)練這樣一個系統(tǒng)所需要的算力和能耗都是龐大的,更糟糕的是,其排放的二氧化碳將是紐約市一整個月的排放量。
機器學(xué)習(xí)的碳排放可以被分為兩種,一種是運營排放,也就是數(shù)據(jù)中心在運行機器學(xué)習(xí)硬件中產(chǎn)生的碳排放;第二種是整個生命周期內(nèi)的排放,不僅包含運營排放,還包含了各個環(huán)節(jié)的碳排放,比如芯片制造、數(shù)據(jù)中心建造等等。考慮到后者涉及更加復(fù)雜的研究,所以大部分碳足跡的研究都集中在運營排放上。
至于如何記錄碳排放,這也很簡單,只需要將訓(xùn)練/推理的時長x處理器數(shù)量x每個處理器的平均功耗x PUE x 每千瓦時的二氧化碳排放即可。除了最后一項參數(shù)需要從數(shù)據(jù)中心那獲取外,其他的數(shù)據(jù)基本都是公開,或取決于機器學(xué)習(xí)研究者自己的選擇。
如何減少機器學(xué)習(xí)的碳足跡圖靈獎得主、谷歌杰出工程師David Patterson教授對現(xiàn)有的機器學(xué)習(xí)的研究和工作提出了以下幾點建議。首先,從模型開始著手,機器學(xué)習(xí)研究者需要繼續(xù)開發(fā)效率更高的模型,比如谷歌去年發(fā)布的GLaM通用稀疏語言模型,相較GPT-3,它多出了7倍的參數(shù),在自然語言推理等任務(wù)上都要優(yōu)于GPT-3。但同樣重要的是它的能耗和碳足跡指標(biāo),根據(jù)谷歌公布的數(shù)據(jù),與使用V100的GPT-3相比,使用TPUv4的GLaM二氧化碳排放減少了14倍,可見模型對于碳足跡的影響。其次,在發(fā)布新模型的時候,他建議也把能耗和碳足跡這樣的數(shù)據(jù)公開,這樣有助于促進機器學(xué)習(xí)模型在質(zhì)量上的良性競爭。
接著是硬件,他指出我們需要像TPUv4或者A100 GPU等,這類機器學(xué)習(xí)能效比更高的硬件。其實這一點反倒是最不需要擔(dān)心的,這幾乎是每個初創(chuàng)AI芯片公司都在嘗試的做法,即便在峰值上不敵這些硬件,也絕對會在能效比上盡可能做大極致。
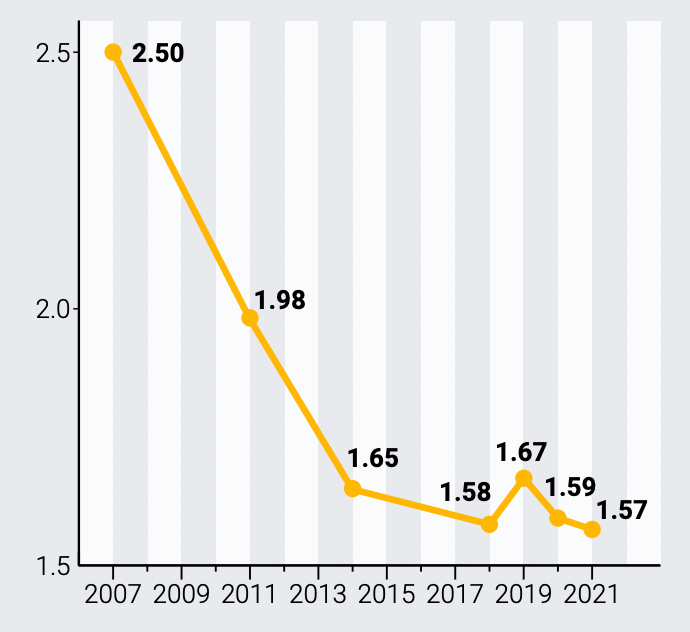
全球大規(guī)模數(shù)據(jù)中心的平均PUE / Uptime Institute
還有就是常見的能效衡量指標(biāo)PUE,大型機器學(xué)習(xí)負載往往要在數(shù)據(jù)中心上運行,而要讓數(shù)據(jù)中心的PUE接近1并不是一件簡單的事。根據(jù)Uptime Institute的統(tǒng)計,各家廠商旗下最大數(shù)據(jù)中心的年度PUE為1.57,就連我國工信部印發(fā)的《新型數(shù)據(jù)中心發(fā)展三年行動計劃(2021-2023)》中提出的最終目標(biāo)也只是將新建大型數(shù)據(jù)中心PUE降低至1.3以下。但好在新建的數(shù)據(jù)中心往往都不會只滿足于這個目標(biāo),而是往1.1乃至1.06這樣的指標(biāo)推進。
可這個指標(biāo)并不是一個死數(shù)據(jù),隨著負載和用量的變動,PUE是在持續(xù)波動的,不少數(shù)據(jù)中心僅僅在建成時發(fā)布了能效指標(biāo),之后就再未公布過任何數(shù)據(jù)了。在這塊做得最好的也還是谷歌,谷歌每年都會發(fā)布年度能效報告,將各個數(shù)據(jù)中心每個季度的PUE公布出來。
不過僅僅只有極低的PUE只能體現(xiàn)出高能耗比,David Patterson教授認為還必須一并公布每個地區(qū)數(shù)據(jù)中心的清潔能源占比。比如阿里巴巴首次發(fā)布的《2022阿里巴巴環(huán)境、社會和治理報告》中就提到了2021年,阿里巴巴在中國企業(yè)可再生能源購買者中排名第一,2022財年阿里云21.6%的電力來自清潔能源。
在雙碳目標(biāo)的提出下,我國其實已經(jīng)落實到了機器學(xué)習(xí)的硬件上,但在軟件和碳足跡透明度這方面還有可以改善的空間。機器學(xué)習(xí)要想做到消耗更低的算力來實現(xiàn)更優(yōu)的效果,就必須從各個環(huán)節(jié)做到節(jié)能減排。
審核編輯:彭靜

