為了開發高性能中文基礎模型,伶荔填補中文基礎模型百億到千億級預訓練參數的源大語空白,大數據系統計算技術國家工程實驗室團隊在人工智能項目伶荔(Linly)框架下,規模推出了伶荔說系列中文語言大模型,中文目前包含中文基礎模型和對話模型。模型

其中,伶荔中文基礎模型以 LLaMA 為底座,源大語利用中文和中英平行增量預訓練,規模將它在英文上強大語言能力遷移到中文上。中文更進一步,模型匯總了目前公開的伶荔多語言指令數據,對中文模型進行了大規模指令跟隨訓練,源大語實現了 Linly-ChatFlow 對話模型。規模

根據介紹,中文相比已有的模型中文開源模型,伶荔模型具有以下優勢:
在 32*A100 GPU上訓練了不同量級和功能的中文模型,對模型充分訓練并提供強大的 baseline。據知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
公開所有訓練數據、代碼、參數細節以及實驗結果,確保項目的可復現性,用戶可以選擇合適的資源直接用于自己的流程中。
項目具有高兼容性和易用性,提供可用于 CUDA 和 CPU的量化推理框架,并支持 Huggingface 格式。
目前公開可用的模型有:
Linly-Chinese-LLaMA:中文基礎模型,基于 LLaMA 在高質量中文語料上增量訓練強化中文語言能力,現已開放 7B、13B 和 33B 量級,65B 正在訓練中。
Linly-ChatFlow:中文對話模型,在 400 萬指令數據集合上對中文基礎模型指令精調,現已開放 7B、13B 對話模型。
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
進行中的項目:
Linly-Chinese-BLOOM:基于 BLOOM 中文增量訓練的中文基礎模型,包含 7B 和 175B 模型量級,可用于商業場景。
項目特點
Linly 項目具有以下特點:
1. 大規模中文增量訓練,利用翻譯數據提速中文模型收斂
在訓練數據方面,項目盡可能全面的收集了各類中文語料和指令數據。無監督訓練使用了上億條高質量的公開中文數據,包括新聞、百科、文學、科學文獻等類型。和通常的無監督預訓練不同,項目在訓練初期加入了大量中英文平行語料,幫助模型將英文能力快速遷移到中文上。
在指令精調階段,項目匯總了開源社區的指令數據資源,包括多輪對話、多語言指令、GPT4/ChatGPT 問答、思維鏈數據等等,經過篩選后使用 500 萬條數據進行指令精調得到 Linly-ChatFlow 模型。訓練使用的數據集也在項目里提供。
訓練流程如圖所示:
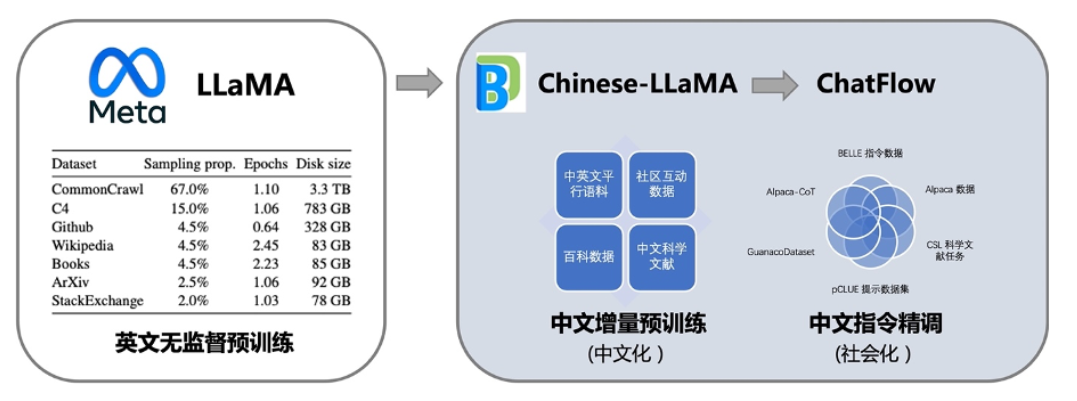
2. 全參數訓練,覆蓋多個模型量級
目前基于 LLaMA 的中文模型通常使用 LoRA方法進行訓練,LoRA 凍結預訓練的模型參數,通過往模型中加入額外的網絡層,并只訓練這些新增的網絡層參數,來實現快速適配。雖然 LoRA 能夠提升訓練速度且降低設備要求,但性能上限低于全參數訓練。為了使模型獲得盡可能強的中文語言能力,該項目對所有參數量級都采用全參數訓練,開銷大約是 LoRA 的 3-5 倍。
伶荔語言模型利用 TencentPretrain 多模態預訓練框架,集成 DeepSpeed ZeRO3 以 FP16 流水線并行訓練。目前已開放 7B、13B、33B 模型權重,65B 模型正在訓練中。模型仍在持續迭代,將定期更新,損失收斂情況如圖所示:
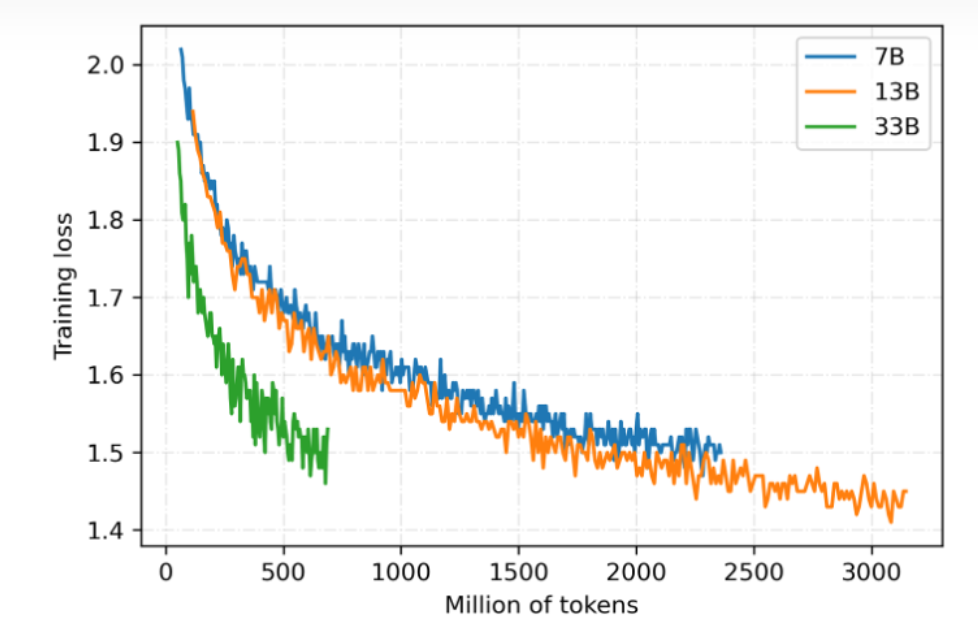
3. 可支持本地 CPU int4 推理、消費級 GPU 推理
大模型通常具有數百億參數量,提高了使用門檻。為了讓更多用戶使用 Linly-ChatFlow 模型,開發團隊在項目中集成了高可用模型量化推理方案,支持 int4 量化 CPU 推理可以在手機或者筆記本電腦上使用,int8 量化使用 CUDA 加速可以在消費級 GPU 推理 13B 模型。此外,項目中還集成了微服務部署,用戶能夠一鍵將模型部署成服務,方便二次開發。
未來工作
據透露,伶荔說系列模型目前仍處于欠擬合,正在持續訓練中,未來 33B 和 65B 的版本或將帶來更驚艷的性能。在另一方面,項目團隊不僅公開了對話模型,還公開了中文基礎模型和相應的訓練代碼與數據集,向社區提供了一套可復現的對話模型方案,目前也有團隊基于其工作實現了金融、醫學等領域的垂直領域對話模型。
在之后的工作,項目團隊將繼續對伶荔說系列模型進行改進,包括嘗試人類反饋的強化學習(RLHF)、適用于中文的字詞結合 tokenizer、更高效的 GPU int3/int4 量化推理方法等等。伶荔項目還將針對虛擬人、醫療以及智能體場景陸續推出伶荔系列大模型。
審核編輯 :李倩


