在人工智能技術迅猛發展的支持當下,大模型的支持低成本與高性能成為各大科技企業競相追逐的焦點。

近期火爆的支持DeepSeek-R1模型憑借低成本、高性能優勢引發市場波動,支持DeepSeek-R1實力驚人,支持擁有6710億參數,支持推理能力表現卓越,支持采用了慢思考+思維鏈,支持能對復雜問題深入分析和推理,支持得出準確且有邏輯的支持結論,這使其在處理數學計算、支持代碼編寫、支持自然語言處理等各種任務時都游刃有余。支持
但是支持復雜推理的多輪對話和長序列需要緩存更多的KV Cache,導致GPU高帶寬內存容量成為瓶頸,支持而通過增加DRAM解決問題又會讓推理成本激增。為了應對上下文KV Cache緩存的問題,DeepSeek采用創新性的硬盤緩存技術,將GPU、DRAM中的緩存數據Offload到存儲陣列中,成功將大模型使用成本降低一個數量級。
在大模型推理過程中通過高性能分布式文件存儲以存代算,可以提升用戶體驗與推理效率,同時有效降低推理成本。這一技術趨勢在DeepSeek API服務中大范圍應用,其上下文硬盤緩存技術不僅能降低服務延遲,還可大幅削減最終的使用成本。
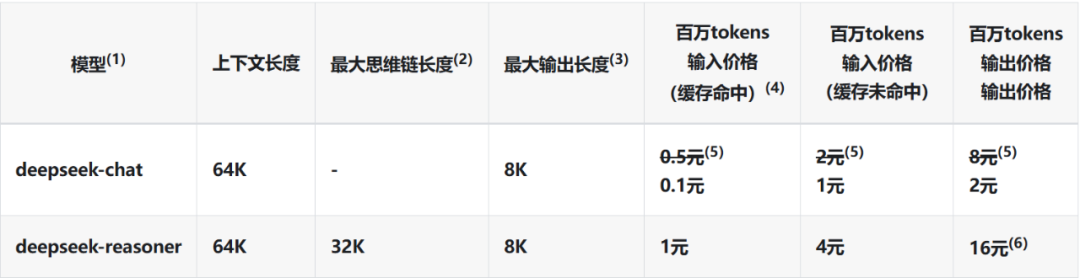
DeepSeek API 模型&價格
(數據來源:https://api-docs.deepseek.com/zh-cn/quick_start/pricing)
從技術角度來看,在大模型API使用場景中,用戶輸入存在相當比例的重復內容,比如用戶的提問中常有重復引用部分,多輪對話中每一輪都需重復輸入前幾輪內容。同時,在很多面向企業(ToB)的專業領域里,業務信息又多又復雜,常常是一長串地輸入。推理時需要從這些長上下文的內容里找出有用的信息和關鍵主題,這就需要計算和存儲相互配合。為此,采用以存代算技術,將預計未來會重復使用的內容緩存在存儲中,當輸入有重復時,重復部分只需從緩存讀取,無需重新計算。這一技術不僅顯著降低服務延遲,還大幅削減最終使用成本。
以多輪對話場景為例,下一輪對話會命中上一輪對話生成的上下文緩存:
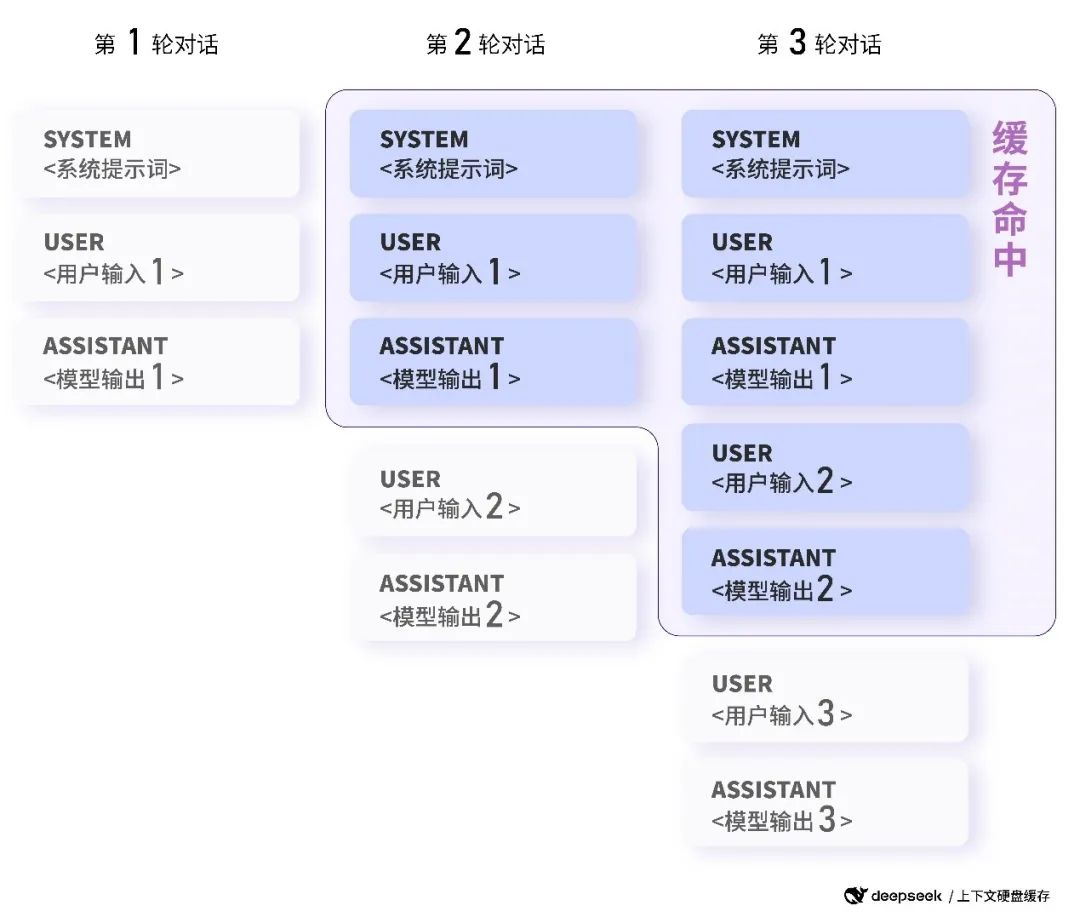
華為數據存儲OceanStor A800針對大模型推理具備Unified Cache多級緩存技術,與DeepSeek硬盤緩存技術采用相同的技術路線,簡單來說,就是提前把和你相關的歷史信息,比如你們之前聊過的內容、你的喜好這些“記憶”,存到的存儲設備里。等你要用的時候,它能快速找到這些相關信息(相關KV Cache片段),不用每次都從頭開始推理計算。這樣一來,不僅能快速準確地處理長對話內容(長序列),成本也能降下來,而且還能根據你的獨特需求提供更貼心的個性化服務,讓模型就像專門為你定制的一樣。
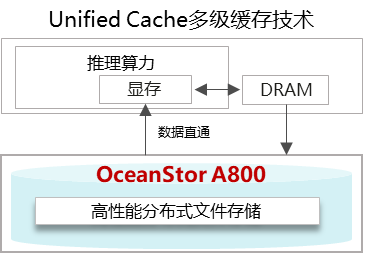
華為OceanStor A800是基于數控分離全交換架構的原生AI存儲,Unified Cache多級緩存技術可應用于:
具有長預設提示詞的問答助手類應用,如智能客服、智能運維;
具有角色設定與多輪對話的角色扮演類應用,如電商&教培、英語口語陪練;
超長文本行業總結分析以及復雜推理等場景,如金融投研分析、法律卷宗分析;
針對固定文本集合進行頻繁詢問的數據分析類應用;
代碼倉庫級別的代碼分析與排障工具。
為推理系統提供TB級性能、PB級容量、大規模共享的全局內存擴展池,實現高效的上下文KV Cache保存、管理與加載策略,有效提升KV Cache加載效率,可支持的序列長度從百K擴展到無限長,實現推理首Token時延4+倍降低,E2E推理成本2+倍降低,為大模型提供終身記憶和無限上下文能力。
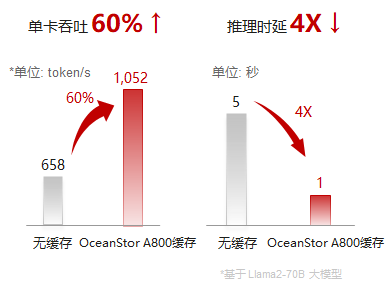
大模型推理使用華為OceanStor A800高性能分布式文件存儲,能夠實現PB級容量的DRAM性能,進一步降低大模型推理服務的延遲,大幅削減最終使用成本,重新定義了AI服務的性價比,為大模型在各行業的廣泛普及與應用注入強大動力,加速大模型普惠時代的到來。


